
Originally posted on 06Sep12 to IBM Developerworks (15,303 Views)
The other day, I was at a customer proof of concept, where the customer asked for 99.9999% availability within the Proof of Concept environment. Let me explain briefly the environment for the Proof of Concept – we were allocated ONE HP Proliant server, with twelve cores and needed to run the following:
- IBM BPM Advanced (BPM Adv)
- WebSphere Operational Decision Management (WODM)
- WebSphere Services Registry & Repository(WSRR)
- Oracle DB (not sure what version the customer installed).
Obviously we needed to use VMWare to deploy the software since installing all of the software on the server (and being able to demonstrate any level of redundancy) would be impossible. Any of you that understand High Availability as I do would say it can’t be done in a Proof of Concept – and I agree, yet our competitor claims they have demonstrated six nines (99.9999% availability) in this Proof of Concept environment – it was deployed on the customer’s hardware; hardware that did not have any redundancy at all. I call shenanigans on the competitor claims. Unfortunately for us, the customer swallowed the claim hook line and sinker. I want to explain why their claim of six nines cannot be substantiated and why the customer should be sceptical as soon as a vendor – any vendor makes such claims. First, lets think about what 99.9999% availability really means. To quantify that figure, that means 31.5 seconds of unplanned downtime per year! For a start, how could you possibly measure availability for a year over a two week period. Our POC server VMs didn’t crash for the entire time we had them running – does that entitle us to claim 100% availability? No way. The simple fact is that the Proof of Concept was deployed in a virtualised environment on a single physical machine – without redundant Hard Drives or power supplies – there is no way we or our competition could possibly claim any level of availability given the unknowns of the environment.
In order to achieve high levels of availability, there can be no single point of failure. That means no failure points in the Network, the Hardware or the Software. For example, that means:
- Hardware
- Multiple redundant Network Interface Connectors
- RAID 1+0 drive array,
- Multiple redundant power supplies,
- Multiple redundant network switches,
- Multiple redundant network backbones
- Software
- Hardened OS
- Minimise unused OS services
- Use Software clustering capabilities (WebSphere n+x clustering *)
- Active automated management of the software and OS
- Database replication / clustering (eg Oracle RAC or DB2 HADP)
- HA on network software elements (eg DNS servers etc)
We need to go back to the Telco and impress upon them that six nines availability depends on all of the above factors (and probably some others!) and not just about measuring the availability of the software over a short (and non-representative) sample period.
Typically this level of HA is very expensive, indeed every additional ‘9’ increases the cost exponentially – that is: six nines (99.9999% availability) is exponentially more expensive than five nines(99.999% availability). I found this great diagram that illustrates the cost versus HA level.
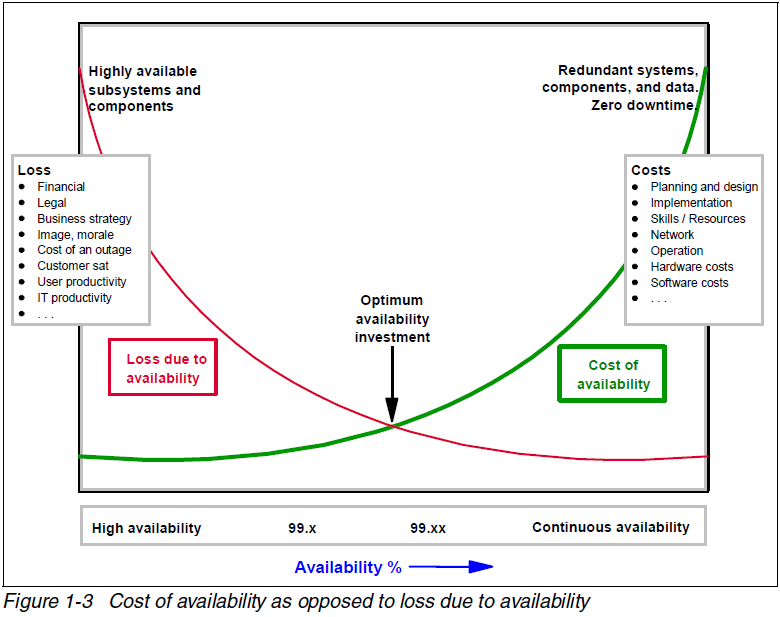
This diagram is actually from a IBM Redbook (See http://www.redbooks.ibm.com/redbooks/pdfs/sg247700.pdf ) which has a terrific section on high Availability – it illustrates how there is a compromise point between the level of high availability (aiming for continuous availability) and the cost of the infrastructure to provide that level of availability.
* Note:
- n is number of servers needed to handle load requirements
- x is the number of redundant nodes in the cluster – to achieve six 9’s, this should be in excess of 2)