Originally poster on 05May10 to IBM Developerworks (13,014 Views)
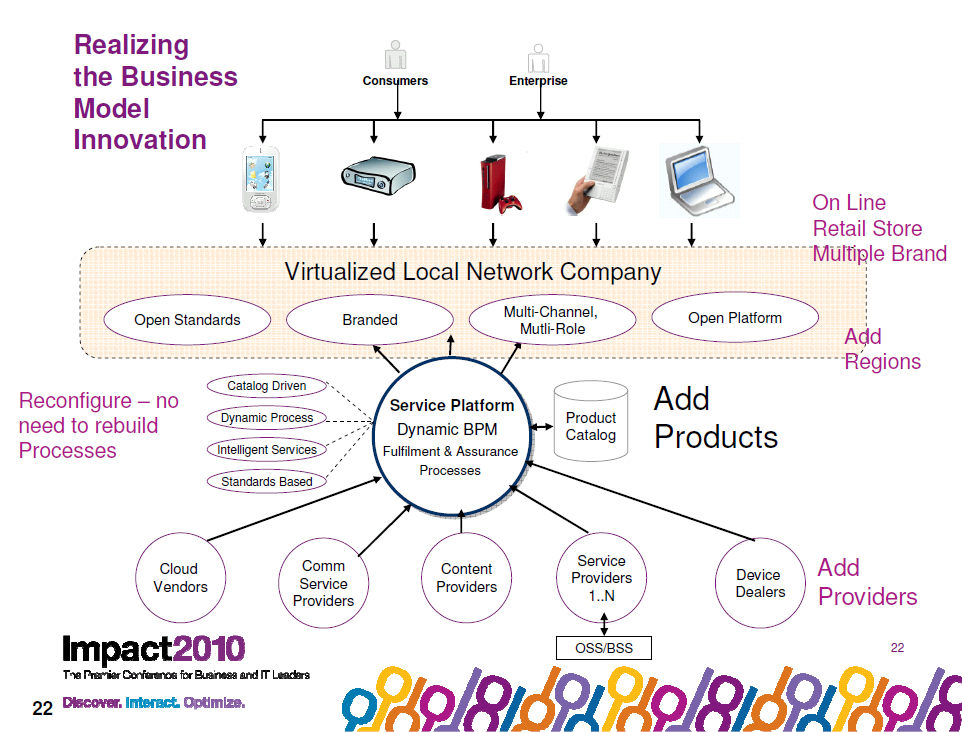
Gridit is a Finnish company that is providing online retail services which was only founded in 2009. They are owned by nine local network providers. Think of them as an aggregated application store that sells a broad range of services and products from those nine network companies as well as third party content providers. They plan to sell services and content such as:
Music
Games
e-books
Access
Data storage
Information Security
Home services
VoIP
IPTV
They do not make exclusive agreements with the content/service providers and provide their customers with freedom of choice. For Gridit, the customer is king – they will seek out new content providers if there is demand from the customers. Gridit also interact with local network providers and 3rd party content providers giving the customers a single point of contact and billing for the services that they resell.
What Gridit are providing is pretty similar to an app store solution we deployed last year in Vietnam which was also a joint venture by a number of Telcos and a bank which provided a retail online store for products and services from those communications providers as well as 3rd party content providers except that Gridit are also offering a hosted wholesale service – I could go to Gridit and build my new company ‘Larmourcom’ and offer products and services from a range of providers that Gridit front end for Larmourcom. Gridit can stand up an online commerce portal for Larmourcom and also provide an interface to the back end providers to allow for traditional and non-traditional service assurance, fulfilment and billing processes.
To achieve this abstraction from the back end providers, Gridit have used WebSphere Telecom Content Pack to provide an architectural framework and accelerator for all of those services. IBM has helped Gridit to map those processes as defined within the TeleManagement Forum’s standards (eTOM, TAM, SID) and map them to the lower level processes to wherever the content or services come from.
Like the Vietnamese app store, Gridit are also using WebSphere Commerce to provide the online commerce and catalogue. For Gridit, the benefits they expect to see (as a result of a Business Value Assessment that was conducted) was 48% faster time to value by using Dynamic BPM and Telecom Content Pack versus a traditional BPM model. That is real business value and a great story for both Gridit and IBM.
Originally posted on 04May10 to IBM Developerworks (9,176 Views)
Ed Jung, Telus Canada
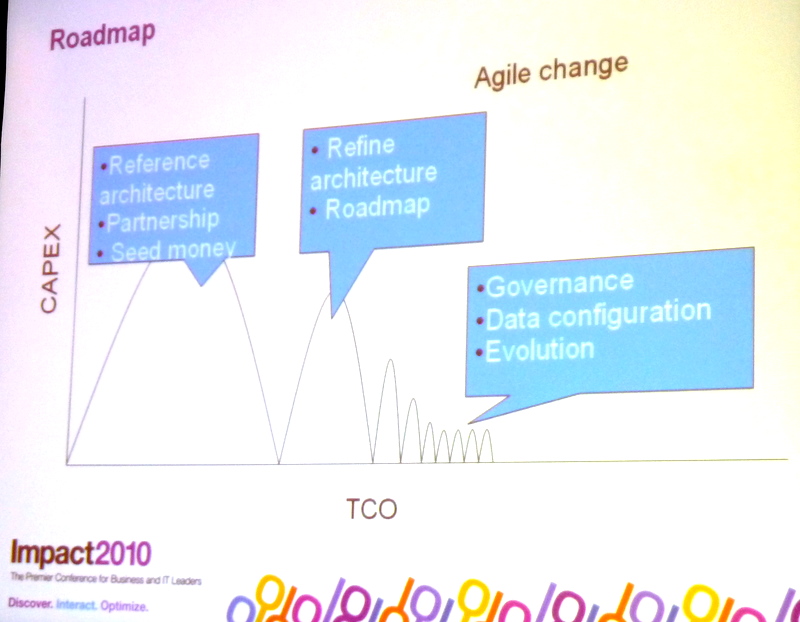
Telus is a Communications Service Provider in Canada, the second largest in their market with 12M connections (wireline, mobile and broadband). Telus have a very complex mix of products, services and systems and they need to maximise their investments while still be able to grow and maintain a lid on their costs. New projects still need to be implemented through good times and bad, so they need an architecture that will allow Telus to continue to grow and maintain costs through a range of economic conditions. Telus selected an agile method/strategy where a reasonable investment early on with the plan to become agile and support new ‘projects’ through small add ons in terms of investment. Ed Jung from Telus characterised the ‘projects’ in the later stages as rule or policy changes which may or may not require a formal release.
To achieve this agility, Telus are using WebShere Telecom Content Pack (WTCP) as an accelerator to keep costs down, while still maintaining standards compliance for their architecture. He sees key success factors as: Selecting a key implementation partner (IBM)
Using standards where possible to maintain consistency
For Telus, they elected to start with fulfilment scenarios within their IPTV system. The basis for this is a data mapping to and from a common model – within the TeleManagement Forum’s standards, that relates to the SID. Ed sees this common model as key to their success.
Dynamic endpoint selection is used within Telus to enable their processes to integrate and participate with their BPM layer. Ed suggest the key factors for a successful WTCP project are:
Adopt a reference architecture
Select a good partner
Seed money for lab trials
Refine architecture
Choose correct pilots
Put governance in place (business and architects)
Configure data / reduce code
Ed thinks that last point (configure data / reduce code) is the best description of an agile architecture that really drive lower total cost of ownership for projects as well as a lower capital expenditure for each project.
Originally posted on 21Feb10 to IBM Developerworks where it got 12,303 Views
Providing a National Broadband Network within a country is seen by many governments as a way to help their population and country compete with other countries. I have been involved in three NBN projects; Australia, Singapore and New Zealand. I don’t claim to be an expert in all three projects (which are ongoing) but I though I would share some observations and comparisons between the three projects.
Where Australia and Singapore have both opted to build a new network with (potentially) new companies running it, New Zealand has taken a different path. The Kiwis have decided to split the incumbent (and formerly monopoly) Telecom New Zealand into three semi-separated ‘companies’ Retail, Wholesale and Chorus (the network), but only for the ‘regulated products’ which for the New Zealand government is ‘broadband’. They all still report to a single TNZ CEO. I have not seen any direction in terms of Fibre to the Home or Fibre to the Node, just defined the product as ‘broadband’. The really strange thing with this split is that the three business units will continue to operate as they did in the past for other non-regulated products such as voice.
As an aside, the Kiwi government not regulating voice seems an odd decision to me – especially when you compare it to countries like Australia and the USA where the government has mandated that the Telcos provide equivalent voice services to the entire population. Sure, New Zealand is a much smaller country, but it is not without it’s own geographic challenges in providing services to all kiwis, yet
Telecom NZ is now Spark
A key part of the separation is that these three business units are obliged to provide the same level of service to external companies as they provide to Telecom and it’s other business units. For example if Vodafone wants to sell a Telecom Wholesale product, then Telecom Wholesale MUST treat Vodafone identically to the way they treat Telecom Retail. Likewise Chorus must do the same for it’s customers which would include ISPs as well as potentially other local Telcos (Vodafone, Telstra Clear and 2Degrees). This equivalency of input seems to me to be an attempt to get to a similar place to Singapore (more on that later). Telecom NZ have already spent tens of million of NZ$ to this point and they don’t have a lot to show for it yet. It seems to me like the Government is trying to get to a NBN state of play by using Telecom’s current network and perhaps adding to that as needed. For the kiwi population, that’s not anything flash like fibre to the home, but more like Fibre to the node and then have a DSL last mile connection. That will obviously limit the sorts of services that could be delivered over that network. When other countries are talking about speeds in excess of 100Mbps to the home, New Zealand will be limited to DSL speeds until the network is extended to a full FTTH deployment (not planned at the moment as far as I am aware)
Singapore, rather than split up an existing telco (like Singtel or Starhub) have gone to tender for the three layers – Network, Wholesale and Retail. The government (Singapore Ltd) has decided that should only be one network and run by one company (Nucleus Connect – providing Fibre to the Home), that there would be a maximum of three wholesale companies and as many retail companies as the market will support. A big difference to New Zealand is that the Singapore government wants the wholesalers to offer a range of value added services – that they refer to as ‘sit forward’ services to engage the population rather than ‘sit back’ services that do not engage the population base. Retail companies would be free to pick and choose wholesale products for different wholesalers to provide differentiation of services.
Singapore, New Zealand and Australia are vastly different countries – Singapore is only 700km2 in size, Australia is a continent in it’s own right and new Zealand is at the smaller end of in between. This is naturally going to have a dramatic effect on each Government’s approach to a NBN. Singapore’s highly structured approach is typical of the way Singapore does things. Australia’s approach is less controlled – due to the nature of the political environment in Australia rather than it’s size and New Zealand’s approach seems somewhat half-hearted by comparison. I am not sure why the NZ government has not elected to build a new network independent of Telecom NZ’s current network.
In Australia on the other hand, the government have set up the Communications Alliance to manage the NBN and subcontract to the likes of Telstra, Optus and others. The interesting thing with that approach (other than the false start that has already cost the Australian Taxpayers AU$30 million) and the thing that sets it apart from Singapore is that the approach doesn’t seem to have any focus on the value added services (unlike Singapore’s approach) – it’s all about the network, even the wholesaler plan for Australia is talking about layer 2 protocols (See The Communications Alliance Wiki. All of the documents I have seen from Communications Alliance are all about the network – all very low level stuff.
Of course, these three countries are not the only countries that are going through a NBN project. For example the Philippines had a shot at one a few years ago – the bid was won by ZTE, but then a huge scandal caused the project to be abandoned. It came back a while later as the Government Broadband Network (GBN) but that doesn’t really help the average Filipino. It’s interesting to see how these projects develop around the world…
Originally posted on 02Feb10 to IBM Developerworks where it got 15,259 Views
On the Wednesday of the week before last (the week before my leave) at about 1am my time, I got an urgent request for a RFI response to be presented back to the customer at Friday noon (GMT+8 – 3pm for me – 2.5 business days for the locals in that timezone). This RFI was asking lots of hypothetical questions about what this particular telco might do with their Service Delivery Platform (SDP). It had plenty of requirements like “Email service” or “App Store Service” and so on. These ‘use cases’ made up 25% of the overall score, but did not have any more detail than I have quoted here. Two to four words for each use case. Crazy! If I am responding to this, such loose scope means I can interpret the use cases any way that I want. It also means that to meet all the use cases (14 in all) ranging from ‘Instance Messaging Presence Service (IMPS)’ to ‘Media Content and Management Service’ to ‘Next-Generation Network Convergence innovative services’ the proposal and the system would have to be a monster with lots of components. The real problem with such vague requirements is that vendors will answer the way they think the customer wants them to, rather than the customer telling them what they want to see in the response. The result will be six or eight different responses that vary so much that they cannot be compared which is the whole point of running the RFI process – to compare vendors and ultimately select one to grant the project to.
On top of the poor quality of the RFI itself, the lack of time to respond creates great difficulties for the people responding. ‘So what, I don’t care, it’s there job’ you might expect them to say and to an extent you are correct, but think about it like this: A short timeframe to respond means that the vendor has to find whoever they can internally to respond – they don’t have time to find the best person. A short timeframe means that the customer is more likely to get a cookie cutter solution (one that the vendor has done before) rather than a solution that is designed to meet their actual needs. A short timeframe means that the vendor may not have enough time to do a proper risk assessment and quality assurance on the proposal – both of which will increase the cost quoted on the proposal.
All of these factors should be of interest to the Telco that is asking for the proposal because they all have a direct effect on the quality and price of the project and ultimately the success of the project.
I know this problem is not unique to the Telecom industry, but of all the industries I have worked with in my IT career, the Telcos seem to do it more often. I could go on and on quoting examples of ultra short lead times to write proposals – sometimes as little as 24 hours (to answer 600 questions in that case), but all it would do is get me riled up thinking about them.
The whole subject reminds me of what my boss in a photolab (long before my IT career began) would say “Quality, Speed, Price: Pick two”. Think about it – it rings true doesn’t it?
Originally posted on 22Jan10 to IBM Developerworks where it got 20,321 Views
Sizing of software components (and therefore also Hardware) is a task that I often need to perform. I spend a lot of time on it, so I figured I would share how I go about doing it and what factors I take into account. It is an inexact science. While I talk about sizing Telecom Web Services Server for the most part, the same principles would be applied to any sizing exercise. Please also note that the numbers stated are examples only and NOT should not be used to perform any sizing calculations of your own!
Inevitably, when asked to do a sizing, I am always forced to make assumptions about traffic predictions. I don’t like doing it, but is is rare for customers to have really thought through the impact that their traffic estimates/projections will have on the sizing of a solution or it’s price.
Assumptions are OK
Just as long as you state them – in fact they could be viewed as a way to wiggle out of any commitment to the sizing should ANY of the assumptions not hold true once the solution has been deployed. Let me give you and example – I have seen RFPs that have asked for 500 Transactions Per Second (TPS), but neglected to state anywhere what a Transaction actually is. When talking about a product like Telecom Web Services Server – you might assume that the transactions they’re talking about are SMS, but in reality, they might be talking about MMS or some custom transaction – a factor which would have a very significant effect on the sizing estimate. Almost always, different transaction types will place different loads on systems.
Similarly, it is rare for a WebSphere Process Server opportunity (at a Telco anyway) to fully define the processes that they will be implementing and their volumes once that system goes into production. So, what do I do in these cases? My first step is to try to get the customer to clear up the confusion. If that fails (I often have multiple attempts at explaining to the customer why we need such specific information – it is in their benefit after all – they’re much more likely to get the right (sized) system for their needs. This is not always successful, so my next step is to make assumptions to fill in the holes in the customer’s information. I am always careful to write those assumptions down and include them with my sizing estimations. At this point, industry experience and thinking about potential use cases really helps to make the assumptions I make reasonable (or I think so anyway 🙂 )
For instance, if a telco has stated that the Parlay X Gateway must be able to service 5760000 SMS messages per day, I think it would be reasonable to assume that very close to 100% of those would be sent within a 16 hour window (while people are awake and to avoid complaints to the telco about SMS messages that come in at all hours of the day – remembering we are talking about applications sending SMS message – nothing to do with user to user SMS messages ) which gets use down to 360000 (5760000/16) SMS per hour or 100 TPS for SendSMS over SMPP – now this is fine for an average number, but I guarantee that the distribution of those messages will not be even, so you have to make an assumption that the peak usage will be somewhat higher than 100 TPS, remembering that we have to size for peak load not average. How much higher will depend on use cases. If the customer cant give you those, then pick a number that your gut tells you is reasonable – lets say 35% higher than average which is roughly 135 TPS of SendSMS over SMPP (I say roughly because if that is your peak load, then as our total is constant for the day (5,760,000) the load must be lower during the non-busy hours. As we are making up numbers here anyway, I wouldn’t worry about this discrepancy, and certainly erring on the side of over sizing is the safer option anyway – provided you don’t over do the over sizing.
Assumptions are your friend
I said I prefer to not make lots of assumptions, but stating stringent assumptions can be your friend if the system does not perform as you predicted and the influencing factors are not as you stated exactly in your assumptions. For instance if you work on the basis of 35% increase in load during the busyhour and it turns out to be 200%, your sizing is going to be way off, but because you asked the customer for the increase in load during the busyhour and they did not give you the information, you were forced to make an assumption – they know their business better that we ever could and if they can’t or won’t predict such a increase during the busyhour, then we cannot be reasonably expected to predict it accurately either – the assumptions you stated will save your (and IBM’s) neck. If you didn’t explicitly state your assumptions, then you would be leaving yourself open to all sorts of consequences and not good ones at that.
Understand the hardware that you are deploying to
I saw a sizing estimate the other week that was supposed to be able to handle about 500 TPS of SendSMS over SMPP, but the machine quoted would have been able to handle around 850 TPS of SendSMS over SMPP; I would call that over doing the over sizing. This over estimate happened because the person who did the sizing failed to take into account the differences between the chosen deployment platform and the platform that the TWSS performance team did their testing on.
If you look at the way that our Processor Value Licensing (PVU) based software licensing works, you will pretty quickly come to the conclusion that not all processors are equal. PVUs are based on the architecture of the CPU – some value a processor at just 30 PVUs per core (Sparc eight core cpus), older Intel CPUs are 50 PVUs per core, while newer ones are 70 PVUs per core. PowerPC chips range from 80 PVUs per core to 120 PVUs per core. Basically, the higher the PVU rating to more powerful each core is on that CPU.
Processors that are rated at higher PVUs per core are more likely to be able to handle more load per core than ones with lower PVU ratings. Unfortunately, PVUs are not granular enough to use as the basis for sizing (remember them though) we will come back to PVUs later in the discussion. To compare the performance of different hardware, I use RPE2 benchmark scores. IBM’s Systems and Technology Group (Hardware) keeps track of RPE2 scored for IBM hardware (System p and x at least) Since pricing is done by CPU core, you should also do your sizing estimate by CPU core. For TWSS sizing, I use a spreadsheet from Ivan Heninger (ex WebSphere Software for Telecom Performance Team lead). Ivan’s spreadsheet works on the basis of CPU cores for (very old) HS21 blades. Newer servers/CPUs and PowerPC servers are pretty much all faster than the old clunkers Ivan had for his testing. To bridge the gap between the capabilities of his old test environment and modern hardware i use RPE2 scores. Since Ivan’s spreadsheet delivers a number of cores required result, I break the RPE2 score for the server down to a RPE2 score per core, then use the ratio between the RPE2 score per core for the new server and the test servers to figure out how many cores of the new hardware are required to meet the performance requirement.
Ok – so now, using the spreadsheet, you key in the TPS required for the various transaction types – lets say 500 TPS of SendSMS over SMPP (just to keep is simple; normally, you would also have to take into account the Push WAP and MMS messages as well not to mention other transaction types such as Location requests which are not covered by the spreadsheet) that’s 12 x 2 cores for Ivan’s old clunkers, but on newer hardware such as newer HS21s with 3 Ghz CPUs, that’s 6 x 2 cores or on JS12 blades it is 6 x 2 cores. Oh that’s easy you say, the HS21s are only 50 PVUs eash easy, I just go with Linux on HS21 blades and that will be the best bang for the buck for the customer, well don’t forget that Intel no longer make dual-core CPUs for server they’re all quad-core, so in the above example, you have to buy 8 x 2 cores rather than 6 x 2 cores for the JS12/JS22 blades.
Note the x 2 after each number: that is because for TWSS in production deployments, you must separate the TWSS Access Gateway and the TWSS Service Platform. The x 2 indicates that the AG and the SP both require that number of cores.
Lets work that through:
Lets first say that TWSS is $850 per PVU. For the fast HS21s – that’s 8 x 2 x 50 x $850 = $680,000 for the TWSS licences aloneFor JS12s – that’s 6 x 2 x 80 x $850 = $816,000 for the TWSS licences alone
Also (and all sales people who are pricing this should know this) the pre-requisites for TWSS must be licensed separately as well. That means the appropriate numbers of PVUs for WESB (for the TWSS AG) and the appropriate numbers of PVUs for WAS ND (for the TWSS SP) as well as the Database. It’s pretty easy to see how the numbers can add up pretty quickly and how much your sizing estimate can effect the prices of the solution.
Database sizing for TWSS
For the database, of course we prefer to use DB2, but most telcos will demand Oracle in my experience. For TWSS, the size of the server is usually not the bottleneck int he environment what is important is the DB writes and reads per second which equates to disk input/output to achieve high transaction rates with TWSS. It is VITAL to have an appropriate number of disk spindles in the database sick array to achieve the throughput required – the spreadsheet will give you the number of disk drives that need to be in a RAID 1 array to achieve the throughput. For the above 500 TPS example, it is 14.6 disks = 15 disks since you cant buy only part of a disk. While RAID 1 will give you striping and consequently throughput across your disk array, if one drive fails, you’re sunk. To achieve protection, you must go with a RAID 1+0 (sometimes called RAID 10) which gives you both mirroring (RAID 0) and stripping (RAID 1). RAID 1+0 immediately doubles your disk count so we’re up to 30 disks in the array. Our friends at STG should be able to advise on the most suitable disk array unit to go with. In terms of CPU for the database server, as I said, it does not get heavily loaded. The spreadsheet indicates that 70.7% of the reference HS21(Ivan’s clunker) would be suitable, so a single CPU JS12 or HS21 blade even an old one would be suitable.
Every time I do a TWSS sizing, I get asked how much capacity we need in the RAID 1+0 disk array – despite always asking for the smallest disk’s possible. Remember we are going for a (potentially) large array to get throughput, not storage space. In reality, I would expect a single 32Gb HDD would be able to easily handle the size requirements for the database, so space is not an issue at all when we have 30 disks in our array. To answer the question about what size – the smallest possible – since that will also be the cheapest possible provided it does not compromise the seek and data transfer rates for the drive. In the hypothetical 30 drive array, if we select the smallest drive now available (136Gb) we would would have a massive 1.9 Tb of space available ((15-1) x 136 Gb) which is way over what we need in terms of space, but it is the only way we can currently get the throughput needed for the disk I/O on our database server. Exactly the same principles apply regardless of DB2 or Oracle being used for the database.
Something that I have yet to see empirical data on is how Solid State Drives (SSD) with their higher I/O rates will perform in a RAID 1_0 array. In such a I/O intensive application, I suspect that it would allow us to drop the total number of ‘disks’ in the array down quite significantly, but I don’t have any real data to back that up or to size an array of SSDs.
We have also considered using an in memory database such as SolidDB either as the working database or as a ‘cashe’ in front of DB2, but the problem there is the level of SQL supported by SolidDB is not the same as that supported by DB2 or Oracle’s conventional database. To port the TWSS code to use SolidDB will require a significant investment in development.
Remember : Sizing estimates must always be multiples of the number of cores per CPU
Make sure you have enough of a overhead built into your calculations for other processes that my be using CPU cycles on your servers. I assume that the TWSS processes will only ever use a maximum of 50% of the CPU – that leaves the other 50% for other tasks and processes that may be running on the system. As a result, I always state that with my assumptions as well. As an example, I would say:
To achieve 500 TPS (peak) of SendSMS over SMPP at 50% CPU utilisation, you will need 960 PVUs of TWSS on JS12 (BladeCenter JS12 P6 4.0GHz-4MB (1ch/2co)) blades or 800 PVUs of HS21 (BladeCenter HS21 XM Xeon L5430 Quad Core 2.66GHz (1ch/4co)) blades. I would then list the assumptions that I had made to get to the 500 TPS figure such as:
There is no allowance made for PushWAP or MMS included in the sizing estimate.
500 TPS is the peak load and not an average load
SMSC has a SMPP interface available
All application driven SMS traffic will be during a 16 hour window
etc
What about High Availability?
Well, I think that High Availability (HA) is probably a topic in it’s own right, but it does have a significant effect on the sizing, so I will talk about it in that regard. HA is generally specified in nines – by that I mean if a customer asks for “five nines “, they mean 99.999% availability per annum (that’s about 5.2 minutes per year of unplanned down time). Three nines (or 99.9% available) or even two nines (99%) are also sometimes asked for. Often, customers will ask for five nines, not realising the significant impact that such a requirement will have on the software, hardware and services sizing. If we start adding additional nodes into clusters for server components, that will not only improve the availability of that component, it will also improve the transaction capability and the price. The trick is to find the right balance between hardware sizing and HA requirements. For example: if a customer wanted 400 TPS of Transaction X, but also wanted HA. Lets assume a single JS22 (2 x dual core PowerPC) blade can handle the 400 TPS requirement. We could go with JS22 blades and just add more to the cluster to build up the availability and remove single points of failure. As soon as we do that, we are also increasing the license cost and the actual capacity of the component., so with three nodes in the cluster, we would have 1200 TPS capability and three times the price of what they actually need just to get HA. If we use JS12 blades (1 x dual core PowerPC) which have half the computing power of a JS22, we could have three JS12s in a cluster, achieve 3 x 200(say) TPS = 600 TPS and even if a single node in the cluster is down, still achieve their 400 TPS requirement. With JS12’s, we meet the performance requirement, we have the same level of HA as we did with 3 x JS22s but the licensing price will be half that of the JS22 based solution ( at 1.5 x the single JS22 option).
I guess the point I am trying to get across is to think about your options and consider if there are ways to fiddle with the deployment hardware to get the most appropriate sizing for the customer and their requirements. The whole thing just requires a bit of thinking…
What other tools are available for sizing?
IBMers have a range of tools availbel to help with sizing – the TWSS spreadsheet I was talking about earlier, various online tools and of course Techline. Techline is also available to our IBM Business Partners as well via the Partnerworld web site (You need to be a registered Business Partner to access the Techline pages on the Partnerworld site). For more mainstream products such as WAS, WPS, Portal etc, Techline is the team to help Business Partners – they have questionnaires that they will use to get all the parameters they need to do the sizing. Techline is the initial contact point for sizing support. For more specialised product support (like for TWSS and the other WebSphere Software for Telecom products) you may need to contact your local IBM team for help. If you are a partner, feel free to contact me directly for assistance with sizing WsT products.
There is a IBM class for IT Architects called ‘Architecting for Performance’ – don’t let the title put you off, others can do it – I did it and I am neither an architect (I am a specialist) or from IBM Global Services (although everyone else in the class was!). If you get the opportunity to attend the class, I recommend it – you work through plenty of exercises and while you don’t do any component sizing, you do do some whole system sizing which is a similar process. I am not sure if the class is open to Business Partners, if it is, I would also encourage architects and specialists from our BPs to do the class as well. Let me take that on as a task – I will see if it is available externally and report back.
Sizing estimations is not an exact science
As I glance back over this post, I guess that I have been rambling a bit, but hopefully you now understand some of the factors in doing a sizing estimate. The introduction of assumptions and other factors beyond your knowledge and control makes sizing non-exact – it will always be an estimate and you cannot guarantee its accuracy. That is something that you should also state with your assumptions.
Originally posted on 18Jan10 to IBM Developerworks where it got 13,471 Views
App Stores Background
I know lots of people are saying that Apple invented the Application Store (App Store) for their iPhone/iTouch range of devices, but they would be wrong. App stores have been around for years – I have been a customer of Handango since before I joined IBM’s Pervasive Computing team and that team has been gone for over three years now. Handango are an Internet based app store that have supported multiple handheld PDA and phone platforms. Others that I’ve used in the past include Tucows, although Tucows is more than just mobile applications – they also cover Win32, Linux, Mac etc as well. The big things that Apple did differently from Handango and their Internet brethren was:
Restrict applications to a single platform (I count the iTouch and the iPhone as the
same thing since the key difference lies in the Mobile Phone part, not the computing part of the device)
Restrict the development tooling and platform environment by license restrictions (All applications must be approved by Apple and must not breach their license agreement – you still can’t get a Java Virtual Machine on an iPhone for instance)
Force users to install via their iTunes installation on their PC/Mac or over the air from their device. Not being an iPhone user, I am not 100% sure of this point. Is there an iTunes install for Linux? (Other platforms allow apps the be installed via bluetooth, memory cards, IR and direct USB copying.)
Of course, Apples’ device competitors are trying to catch the same wave that Apple have been riding and deploy their own application store equivalents. We’ve seen efforts from Google, Nokia, Palm and Research In Motion (RIM – makers of the Blackberry) and interestingly, all have been somewhat successful. Successful at attracting developers which is key to then attracting users. Here are the their app stores:
Personally I am not a fan of Apple’s restrictive market practices and much prefer the more open ecosystem that surrounds the Symbian and Windows mobile platforms. I have in the past written applications for Palm Garnet (nee PalmOS), Symbian and Windows Mobile for use within a corporate environment. Something that is not possible with Apples licensing policies and forcing developers to upload apps to the App Store so that Apple can approve them and then include them in the App Store catalogue. If I only want to write an application for my customer, I cannot deploy it directly to the customer’s iPhones unless they have been jailbroken – the only alternative is for Apple to look at and approve the application then sign it. While the others also have the concept of signed and certified applications, you can install unsigned or un-certified applications on the other major platforms if you want (except for Android which appears to be going down a similar if less restrictive path to Apple).
Telcos and App Stores
In the past year as Telcos all around the world have watched Apple’s App Store take off and seen their interaction with the iPhone subscribers being reduced to the supplier of the pipe to the Internet – way down from the high value position that most carriers aspire to in order to improve ARPU. I’ve seen requests form many Telcos in that time for Application Store or Widget Store capability. The telos – understandably – want to raise their profile in the eyes of the subscriber and their worth in the value proposition. I have seen request for proposal documents from telcos in China, Taiwan, Vietnam, USA and queries from telcos in Thailand, Philippines, Singapore, Japan and other countries. App/Widget Stores are certainly one of the topics of the moment for Telcos.
The key differentiation that a Telco has that separates it from Apple’s App Store are:
Support for multiple smartphone platforms – Symbian, Blackberry, Windows Mobile, Garnet (and presumably soon; WebOS and Android as well)
The ability to sell things other than on device applications – this might include pre-paid top ups, ringtones, ringback tones, telco hosted applications (that could be delivered by the Telco’s Service Delivery Platfform (SDP)
In fact, IBM has won and has (partially at this stage) implemented an app store in Vietnam. Because of the Telecom environment in Vietnam, this App Store is not actually within a telco, but is instead an external company*. The app store was implement with a combination of WebSphere Portal (to provide the user interface) and WebSphere Commerce (to provide the catalog and sales part of the App Store and WebSphere Message Broker for Integration requirements. I was involved from the very initial stages of that project.
The company intends to launch a Mobile Commerce and Advertising Platform (MCAP), which is a multi-channel platform enabling its members to do small value electronic transactions (or m-commerce and e-commerce. Some of their use cases include:
Mobile phone content buying and selling (logo, ring tone, ring-back-tone…)
Purchasing small value digital products such as software, e-books, etc.
Buying and Selling of other services and products such as information services, Souvenir, electronic tickets, promotion vouchers, etc.
Low value payment services, such as prepaid top-up, game top-up, bill payment, etc.
Online marketing, advertisement and promotion services over Internet and Mobile.
I don’t often get involved in WebSphere Commerce projects (it tends to be a very specialised field) we do have a number of Telcos who are using WebSphere Commerce, not necessarily in App Stores, but based on the experience in Vietnam, it would not be a big leap to add that capability to their existing deployments.
The usage of WebSphere Portal provides a easy and extensible user interface primarily targeted at the PC, and with the addition of the Mobile Portal Accelerator (nee WebSphere Everyplace Mobile Portal Enable) to the existing Portal, that user interface can be extended to over 10,000 separate devices providing subscribers with an optimised experience for their device.
Where does this leave those Telcos who haven’t made the leap to their own app store? In my opinion, they still have time to catch the wave, and certainly if they want to avoid the Apple effect and being reduces to a bit pipe provider, then they need to do something to add value in the eyes of the subscriber. Apple’s model doesn’t help them with that, but perhaps the other device specific app stores wont be so carrier unfriendly. I will see what I can find out on this issue and report back in another post.
Buy for now
* Once that customer has agreed to be a formal reference, I will share additional details in a future post.
If you want some background reading on App Stores, here are a couple of articles I would suggest:
Originally posted on 31Dec09 to IBM Developerworks where it got 10,998 Views
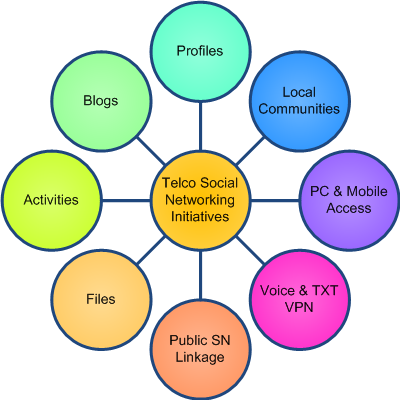
As I see it, Telcos (particularly in counties that I deal with) are in a perfect position to transform their subscriber’s enthusiasm for social networking into real business benefits Combining traditional Calling Circle Applications (aka Family & Friends, or VPNs as the Telcos would call them) with online (PC or Mobile) communities to share information. These could be short-lived around:
Religious event
Public Holiday
Sporting finals
Wedding Anniversary
21st Birthday Party
Or they could be longer term communities such as :
Kindergartens
Scout Troups
Football Clubs
Fan clubs
Church Groups
Service Clubs (Lions, Apex, Rotary etc)
These are just some that come to mind off the top of my head. I am picturing discounted call and text rates for community members as well as discounted data rates for mobile access to the web community including blogs, activities, profiles, discussions etc. Think about these sort of integrated scenarios for Telcos:
Sending SMS messages to blog subscribers every time that blogger posts a new blog
Emails or SMS message to a community – based on either their profile or their current location.
Microblogging aggregation – the subscriber sends a SMS to a shortcode, which then updates all the other microblogging services that subscriber uses (Facebook, Twitter, MySpace, Freindster etc)
Write blog posts on your mobile phone either via a MMS message (including images, video or audio), the phone web interface, an email interface or (for shorter entries) SMS messages.
Bloggers could recieve SMS messages whenever someone comments on their posts
…. the list goes on…
In these days where churn is a significant issue for most Telcos – especially in countries where mobile number portability (MNP) has been introduced, anything a telco can do to make themselves more sticky for their subscribers is a good thing. Also add to that the potential additional revenue from additional data and messaging usage and we have a proposition that lot of telcos would be interested in. I wouldn’t see this as having a major effect on ARPU, but every little bit helps.
I can picture a wide range of services that telcos could combine with their Social networking offerings that would draw out additional revenue from their subscribers. While there are plenty of Internet based companies offering blogging, file sharing, profiles, microblogging etc, none of them have the established relationship that a Telco has with it’s subscriber base. Additional, very few of them have a local presence outside of their home country. Telcos are localised in nature – either through government heritage, Government regulation, Language or social reasons – Telcos need to take advantage of that fact. OK, their in country competitors have the same advantage, but in this race, the real competitors are the Internet providers. Obviously, a Telco that can move on this territory before their local competition will have a significant advantage in the marketplace.
My gut tells me that within each country, we are just waiting for the first Telco to offer these sort of converged services before all the others in that marketplace decide that they need to as well – the Domino effect.
Speaking about the Domino effect, I am struck by the irony of the naming of that principle and what is happening in the Vietnam telco market right now. The US Government coined the term the Domino effect to justify entering the Vietnam War in support of South Vietnam (to prevent the fall of the rest of South East Asia to communism), yet in the Telecom industry in Vietnam, we are seeing a Domino effect with respect to Service Delivery Platforms right now – one telco goes down the SDP path, so now they are all going down the SDP path…
Now that I have rambled onto the subject of SDPs, a telco could offer Social Networking services without having a SDP in place, but in order to offer true integration between the Social Networking offering and the traditional telco services, a SDP will be required unless they want to go down the custom code path and I think we all know where that ends up – Spaghetti Junction!
Originally posted on 30Dec09 to IBM Developerworks where it got 9,113 Views
As I alluded to in my earlier post (Telcos capitalising on Social Networking tools), Telcos can use Social Networking tools to their advantage in a number of ways. I also mentioned the Idea Factory for Telecom – an adaptation of the basic Idea Factory offering now owned by Software Group Services for Lotus. This offering was originally put together by the High Performance On Demand Services (HiPODS) team and had no less than six servers minimally required for the offering. That is because the Idea Factory (or Innovation Factory as it was previously known but renamed due to trademark issues) was originally offered well before Lotus Connections was released. These days, small to medium implementations can be done with Lotus Connections, IBM Mashup Center and a number of templates and add-ons (widgets) for Connections. A Proof of Concept could potentially be done with a single server. Larger Idea Factory implementations – particularly where Telcos are hosting the service for their enterprise customers and MNVOs would also require a WebSphere Portal Instance as well.
Probably the best explanation I can give to you of the Idea Factory is for you to watch the recorded demonstration I have available below – in fact I have quite a number of variations of the same demo customised for different Telcos – the demo below the most recent which was recorded before Connections 2.5 was released and so was done with beta version of Connections – see if you can spot the fault in the video! I tried to cover it up as much as possible because I needed to show this video to customers, but it’s in there and you will see it if you know what you are looking for….
For online access to the latest Idea Factory (V2) recorded demo – just launch it below… Also note that this is a lower resolution version for online use. I also have a larger version that I used for offline demos, it is 24Mb in size so I will share that with anyone that requests it rather than make it generally available.
Way back in 2007, there was a good whitepaper about the Idea Factory – I have uploaded it to Collaboration_to_innovation-leveraging_web20.pdf. This document is now quite out of date with respect to the technology used to deploy the Idea Factory (then called the Innovation Factory) – these days, we would use Lotus Connections 2.5 as the base platform and add widgets for the polling/surveys requirement and set up activities templates to manage the ideation process, then use IBM Mashup Center rather than QED Wiki which was a IBM Research developed Mashup Environment (check youhtube.com – there are lots of QEDWiki demos available).
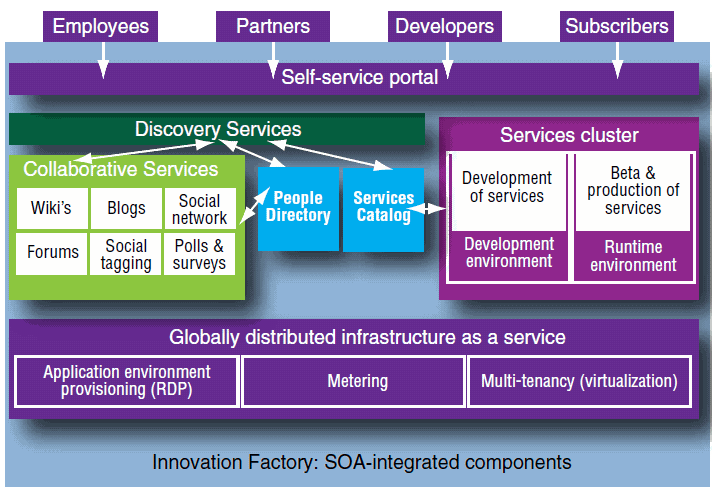
The Idea Factory for Telecom fosters collaboration by incorporating a self-service portal for consistent user experience and integration. Aside from this limitation, the concepts expressed in the whitepaper and the usage of the Idea Factory remains relevant. I guess one point that this whitepaper makes it that IBM has been in this Web 2.0 game for a while now – longer than we have had Generally Available product to support the concepts.
If we look at the above diagram, Lotus Connections will take care of most of the Collaborative Services and the Portal (UI) requirements while IBM Mashup Center takes care of the Services Cluster and the Services Catalog (called the Widget Catalog in the Mashup Center).
Originally posted on 18Dec19 to IBM Developerworks where it got 8,218 Views
The announcement by Telstra* the other day of it’s social networking guidelines for employees (See Telstra’s 3Rs of Social Media Engagement and their online training class ) got me thinking about how Telcos should be using Social Networking tools and trends both internally and externally. OK, Internally, a Telco is like any other big company when it comes to collaboration among it’s staff. Social Networking tools help employees to make contacts, learn and share more, find information more rapidly and maintain social networks beyond the physical boundaries of their own work location. If you’re curious about what I am talking about, I recommend you have a look at the great videos on YouTube from Jean Francois Chenier (An IBMer). I have embedded the first of the series below:
It’s pretty easy to see how within any large company, social networking software such as Lotus Connections makes sense provided you have enough people who actually use it – it seems to me to be something like groups calendaring – it is dependent on a significant proportion of the user population using the tool to make it effective. The way I see it, it is only a small step beyond the internal deployment of social networking tools to extend to a Telco’s trading partners. That might include vendors, resellers (of Telco products – I was initially thinking retail, but that could include MNVOs), enterprise customers and others. Situations where employees of the Telco and employees of external companies need to work together and share information and collaborate – share idea, files, information – generally collaborate would seem to be a valid deployment of social networking tools.
IBM already has an offering that uses social networking tools to build communities around the Ideation (Idea generation and growth) process, a kind of virtual brainstorming combined with idea and through sharing. The intent of the offering is to make it easier for companies to find and help to evolve idea for the next product to take to market. In a Telco, this might be idea such applications like “Meet-on-click”** that a telco could take to market. That offering is called the ‘Idea Factory’ and is not actually unique to the Telecom industry. Kraft foods use the Idea Factory to come up with new ideas for product packaging. When deployed in a Telco, we often combine the Idea Factory with IBM Mashup Center (recently V2.0 of Mashup Center was released by the way) – an offering I usually call the “Idea Factory for Telecom”. The Mashup Center is used as a rapid prototyping environment for the ideas that are evolving within the Idea Factory. In my view, this is a great way to build an active and dynamic developer community for the Telco.
China Telecom have demonstrated how effective the Idea Factory can be in a Telco environment – with a year on year improvement of 900% in a competition to find new applications (3 to 27 new products). Their Idea Factory deployment predated IBM Mashup Center, so they didn’t get the benefit of a rapid prototyping tool which I believe could increase the quality of the new product ideas even further.
While I am a big fan of the Idea Factory, I see that as just a starting point for social networking tools hosted by a Telco that extend beyond just their developer community and into their (much) larger subscriber base. Think about building many local communities based around schools, churches, scout troops, national holidays, religious events, local football teams, mothers groups… anything really. The community would have access to a shared virtual community on the web accessible from a PC or (more importantly for many developing nations) from a mobile phone, they would have microblogging, blogs, files sharing, discussion forums, profiles contacts AND be tied into more traditional Telco services such as calling circles. The Telco could provide discounted call and text rate between community members. Sound good? I think so. For the Telco I see a number of benefits:
Decreased likelihood to churn – increased ‘stickiness’
Stronger loyalty to the Telco brand
Increased revenue due to increase in call and text volumes and increased mobile data usage once a reasonable proportion of the community is using the tools
An additional weapon against the Internet based competitors (such as Facebook, Skype, Twitter, Instagram etc)
Telcos in my opinion have a significant advantage over the Internet companies when it comes to offerings like this. They have:
An existing relationship (post or pre paid) customer
More local footprint via people on the ground and reseller/franchisees
Existing monetary arrangements with the customers
Greater trust by customers (typically)
Telcos could easily become the local aggregation point for social networking within that community – for instance with a Facebook connection, subscribers could update their Facebook wall without the need to launch Facebook. Microblogging entries could automatically update status in Facebook, LinkedIn, MySpace and sent a tweet out on twitter.
I think this is going to be big – web based social networking giants like Facebook, MySpace and LinkedIn have proved how popular web based social networking can be – add the local context to it and I think you have a winner for Telcos in many markets.
Now that I have started this thought, I think the next few posts could well be along similar vein – looking at the Idea Factory for Telecom, Telco focused Developer Ecosystems, User generated content and Public focused and Telco integrated social networking capabilities….
Originally posted on 26Nov09 to IBM Developerworks where it got 11,308 Views
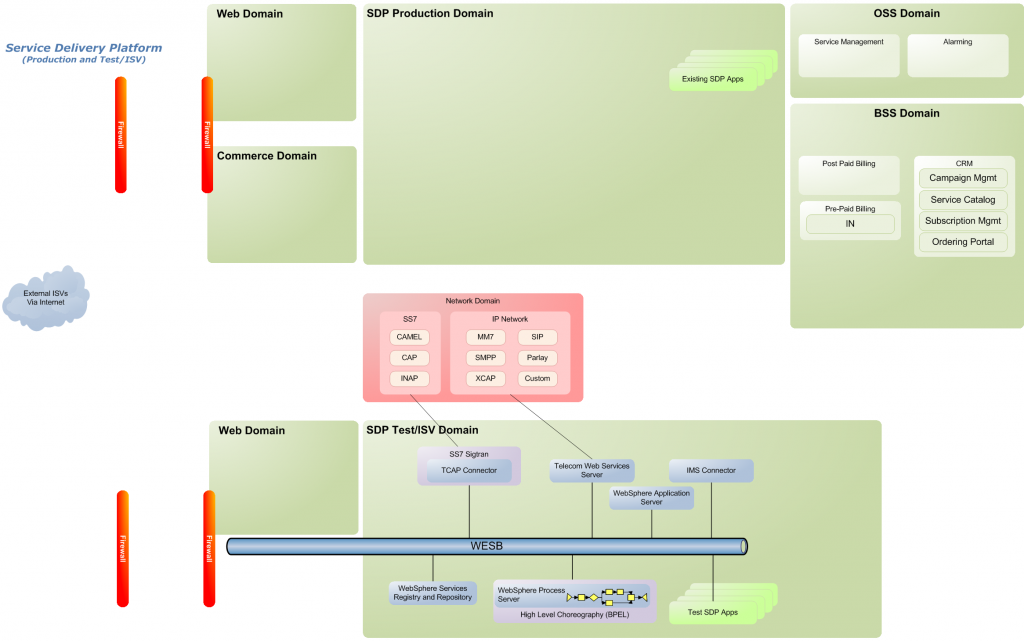
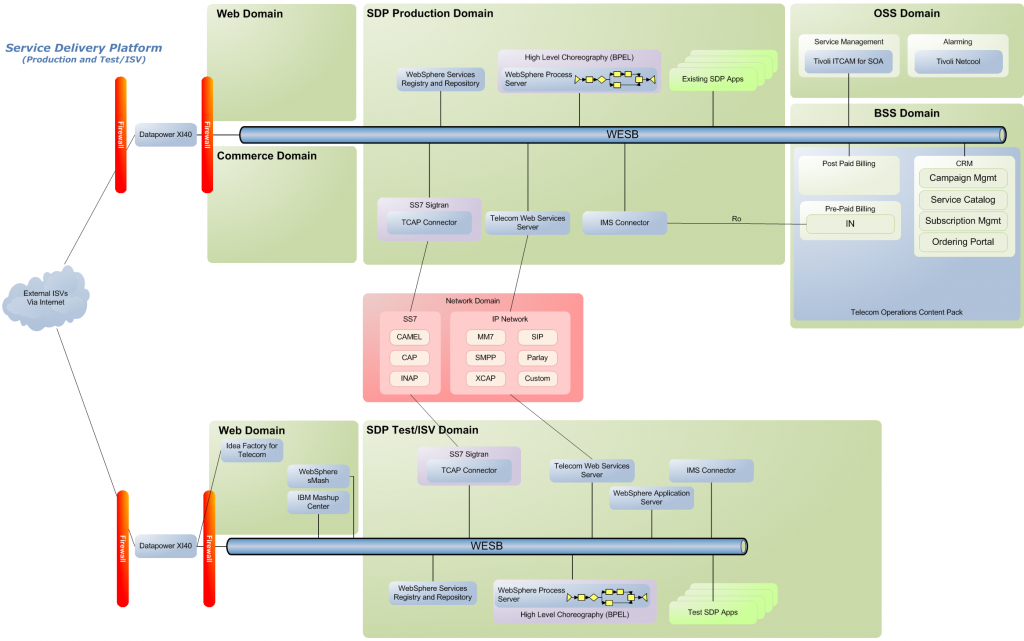
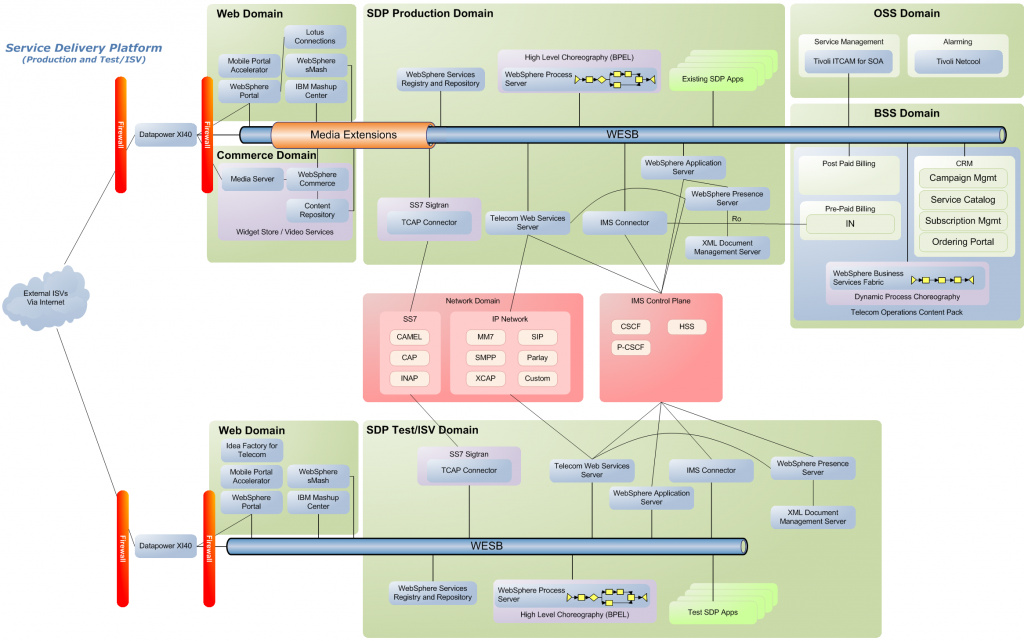
I had a request on the other week to create a number of topology diagrams that showed how a Telco might start small and grow their environment to add new capabilities and services. This was specifically for a telco in Vietnam, but I figured it would make sense to generalise the presentation and the images to make it usable for other opportunities. We’ve had a similar request from other telcos recently as well. The presentation step through 11 phases from a pilot/trial environment through to a full blown system. Each slide has speaker notes explaining what is being added at each phase in terms of products and capabilities. This presentation is not meant to make any recommendations on how to evolve form a small system to a more complex and capable one. What it is supposed to illustrate one possible evolution… Note that it focuses only on the IBM components and some other components would also be required for some phases (such as a transcoding engine in the media extension phase).
Below are three of the diagrams – Phase 1, Phase 6 and Phase 11 and the speaker notes that go along with that phase – to give you a feel for the flow…
Phase 1 – Test Environment
Phase 1 – Test Environment
At this first stage, an initial deployment might be considered a proof of concept or a trial – which could become the test and or ISV environment, The functions that this could offer are:
Composite applications that bring together functions provided by the network. For instance an application that consumes SMS messaging and integrates the location of the handset into an app.
WSRR will get them down the path of SOA Governance – it is important to get this in early to ensure that the governance model is maintained and the Telco will now need to rework services that are created at this stage.
Complex workflows and business processes can be built which include human tasks (such as prototype processes for the production implementation )
Phase 6 – Developer Ecosystem including Web 2.0
Phase 6 introduces the Developer Ecosystem components such as :
Idea Factory for Telecom – which will help make a dispersed group of developers into a community. It enable the sharing of ideas and a framework for the Telco to manage the evolution of the ideas that are generated within the community. It also provides a rapid prototyping capability via…
IBM Mashup Canter which allows users to drag widgets onto a workspace and simply wire them together. It is both the development and the runtime architecture. This means that developers don’t need deep development skills in order to build new applications.
WebSphere sMash which provides a PHP and Groovy scripting environment (both development using the Dojo toolkit and the runtime environment)
This combined with the web services exposure deployed in phase 4 means that the developer ecosystem can now cater for all levels of developers – those with no skills can use the drag and drop mashup environment, script developers can use sMash and more advanced developers can use the web services interface. In the backup slides there is an illustration of this.
For advanced developers the Telco can support developers across a range of IDEs ranging from Rational and Eclipse (where we have Telecom Toolkits available for free) to other IDEs (such as Microsoft Visual Studio or Sun Netbeans) where the IDE has tools to assist developers with consuming web services. In all the IDEs, developers will consume the Web Services Description Language (WSDL) file from a UDDI directory in the DMZ. The UDDI directory (part of WPS) is populated from the WSRR internal services repository.
Phase 11 – IMS integration and extension
When the Telco goes down the IP Mulitmedia Subsystem (IMS) path, the software deployed already has IMS enablement, but at this point we can also add WebSphere Presence Server (PS) and WebSphere XML document Management Server (XDMS – formerly WebSphere Grouplist Manager) which provides IMS services for the IMS services plane. The core infrastructure that was deployed way back in phases 1 and 2 are critical to the IMS Services plane.
It is important to understand that the phases I have split them down into are purely arbitrary and are not necessarily what would happen in a real telco. Which function occurs at what point and in combination with other functions is something that must be driven by the business requirements of the telco. The intent is to illustrate how a telco could start small and add function incrementally building on the previous investments.