Originally posted on 4Sep17 to IBM Developerworks (10,430 Views)
I wouldn’t normally just post a link to someone else’s work here, but in this case Frank Wong – a colleague of mine at my new company (DGIT Systems) has done some terrific work in helping to eliminate the miss-match between the data model used by the TMF’s REST based APIs and the TMF’s Information Model (SID). I know this was an issue that IBM were also looking to resolve. In the effort to encourage the use of a simple REST interface, the data model used in the TMF’s APIs has been greatly simplified from the comprehensive (some might say complex) data model that is the TMF’s Information Model (SID). This meant that a CSP who is using the SID internally to connect internal systems needed to map to the simplified API data model to expose those APIs externally – there was no easy one-to-one mapping for that mapping which meant that the one could not simply create a API for an existing business service (eTOM or otherwise) – a lot more custom data modelling work would be required.
Originally posted on 30Aug17 to IBM Developerworks (11,517 Views)
Across many industries, including the Telecommunications sector, there seems to be a strong movement towards a MicroServices Architecture and (somewhat) away from Service Oriented Architecture. I’ve seen this move in a CSP here in Australia. The TeleManagement Forum have a significant project that is trying to standardise the REST APIs that a CSP might publish.
The TMF state:
“TM Forum’s Open API program is a global initiative to enable end to end seamless connectivity, interoperability and portability across complex ecosystem based services. The program is creating an Open API suite which is a set of standard REST based APIs enabling rapid, repeatable, and flexible integration among operations and management systems, making it easier to create, build and operate complex innovative services.TM Forum REST based APIs are technology agnostic and can be used in any digital service scenario, including B2B value fabrics, Internet of Things, Smart Health, Smart Grid, Big Data, NFV, Next Generation OSS/BSS and much more.”
“TM Forum is bringing different stakeholders from across industries to work together and build key partnerships to create the APIs and connections. The reference architecture and APIs we are co-creating are critical enablers of our API program and open innovation approach for building innovative new digital services in a number of key areas, including IoT applications, smart cities, mobile banking and more.”
Laurent Leboucher, Vice President of APIs & Ecosystems, Orange
I’ve been a part of a number of projects where these REST APIs have been exposed primarily to a CSPs trading partners – my very first Service Delivery Platform exposed APIs to external developers. Back then, it was Parlay X Web services (REST didn’t really exist and certainly there to external developers.were no Telco standards in place for REST based interfaces) that exposed the functionality of network elements to 3rd party developers. With many of the APIs that the TMF have defined, they seem to be more focused on OSS/BSS functions instead. Now that the TMF have quite a number of Open APIs defined, there are some network focused APIs that are coming onto the list – for instance, a Location API would have typically be exposed using the ParlayX Web Services or ParlayREST REST interfaces to the network’s Location Based Server (LBS). As a result, there does seem to be a small amount of crossover between the new TMF APIs and the older ParlayREST APIs.
Does this mean that the new TMF OpenAPIs are of no use? Not at all. There are certainly advantages to exposing functions that a CSP has to external developers and REST based OpenAPIs make the consumption of those functions easier than the ParlayX web services or Parlay CORBA services have been in the past. Ease of consumption is not to be underestimated. An API that is easy to include in an application and provides a real capability that would have been otherwise difficult to provide stands a much greater chance of wide usage.
Sure, there is a place for externalising the OSS/BSS functions of a CSP. Trading partners could place orders against a CSP, they could bill to a subscriber’s post or pre-paid accounts, they could update the subscriber profile held by the CSP. All relevant use cases for externalising the TMF Open APIs.
The big question in my mind is will REST APIs be of use internally?
REST based APIs being easier to integrate internally will drive some value. But in CSPs that have significant investments in a Service Oriented Architecture (SOA), I’m struggling to see the business value in abandoning that in favour of a MicroServices Architecture where there is no common integration tool, no common orchestration capability, rather lots and lots of point to point integrations through REST APIs.
For those of us that have been around a while, you will have seen point to point integrations and the headaches they cause – complex dependencies in mesh architectures make maintenance hard and expensive. Changing a (say) billing system that is integrated through multiple point to point connections is a nightmare – even if they have a standardised API describing those interfaces. The plane truth of the matter is that not all of those interfaces will be adequately described by the TMF’s Open APIs, so custom specifications APIs will arise and make swapping out the billing system expensive. Additionally, not all of a CSPs internal systems will have TMF Open API compliant interfaces – many won’t even support REST interfaces natively. Changing all of a CSP’s systems to ensure they have a REST interface is a non-trivial task.
A Hybrid environment may be needed.
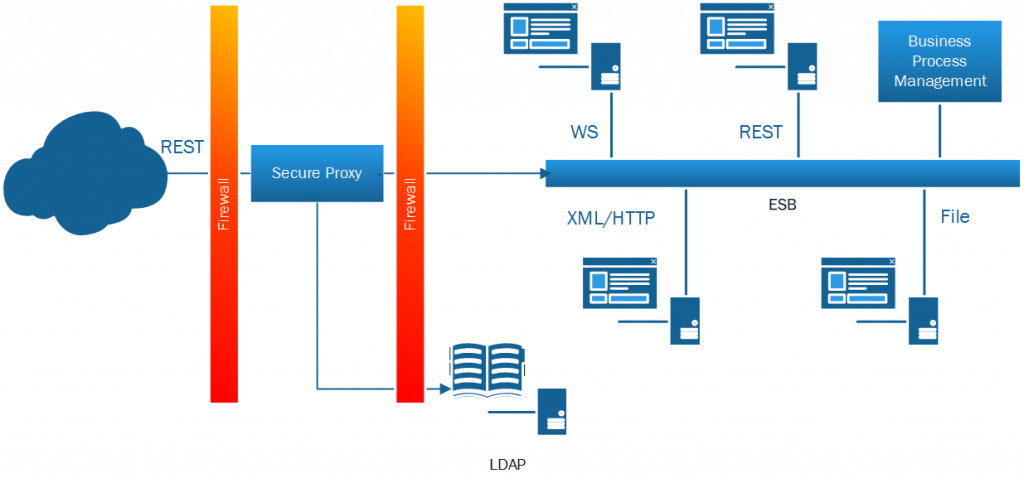
I’d suggest that a Hybrid approach is needed – existing Enterprise Service Busses may be able to interface with REST APIs – certainly IBM’s Integration Bus and the (now superseded) WebSphere Enterprise Service Bus could connect to REST APIs just as easily as they could connect to Web Services, Files and other connectivity options. The protocol transformation capabilities of a ESB are able to provide REST APIs to systems that would have otherwise not supported such modern interfaces. Similarly, where a function is not provided by a single system, a traditional orchestration (BPM) capability can coordinate multiple systems to provide a single interface to that capability even if (behind the scenes) there are multiple end point systems involved in providing the functionality of that transaction/interface. The diagram below shows my thinking of what should be in place….
Originally posted on 6Jun17 to IBM Developerworks (11,950 Views)
Think about it – orchestration is everywhere in a Telco – the Order to Cash process, The Ticket to Resolution process, the service and resource fulfilment process and even the NFV MANO processes. Orchestration is everywhere…
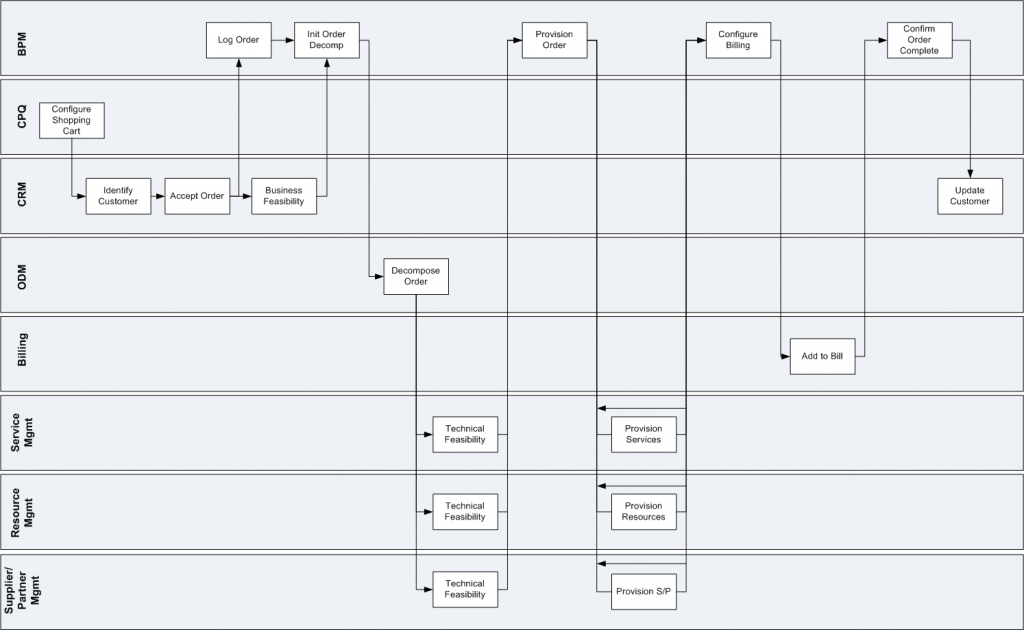
There is a hierarchy to processes in a Telco – just as the TMF recognises that there is a hierarchy in business services (within the eTOM Process Framework). At the highest level, the Order to Cash process might look like this:
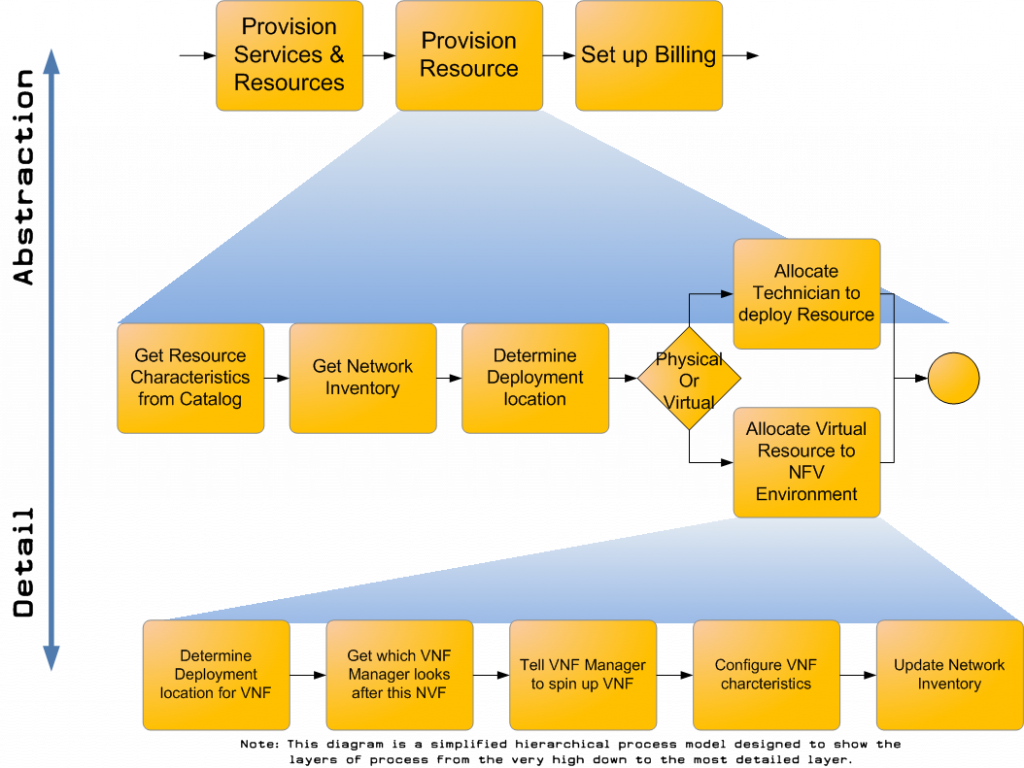
Each task in this swimlane diagram will have multiple sub-processes. If we delve down into the provision resources task for instance, a CSP will need processes that will interrogate the resource catalog and network inventory to determine where in the network that resource can be put and what characteristics need to be set, then tell the resource manager to provision that resource. If it’s a physical resource, that may involve allocating a technician to install the physical resource. If it’s a virtual resource such as a Virtual Network Function (VNF) then the Network Function Virtualisation (NFV) orchestration engine will need to be told to provision that VNF. If we go one level deeper, the NFV Orchestration engine will need to tell the NFV Manager to provision that VNF and then update the network inventory.
Perhaps the diagram below will help you to understand what i mean:
This diagram is a very simplified hierarchical process model designed to show the layers of process. As you can see, there are many layers of orchestration required in a CSP and as long as the orchestration engine is flexible enough and can handle the integration points with the many systems it needs to interact with, there is no real reason why the same orchestration engine couldn’t be used by all levels of process.
Over the past couple of years as NFV has risen significantly in popularity and interest, I’ve seen many players in the market talk about orchestration engines that just handle NFV orchestration and nothing else. To me, that seems like a waste. Why put in an orchestration engine that is just used for NFV when you also still need orchestration engines for the higher process layers as well? I’d suggest that a common orchestration and common integration capability makes the most sense delivering:
High levels of reuse
Maximising utilisation of software capabilities
Common Admin and Development skills for all levels of process (be they business focussed or service or resource focussed)
Common tooling
Common Integration patterns (enabling developers and management staff to work across all layers of the business)
Greater Business Agility – able to react to changing business and technical conditions faster
There are a number of Integration platforms – typically marketed as Enterprise Service Buses (ESB) that can handle integration through Web Services, XML/HTTP, File, CORBA/IIOP even Socket/RPC connections for those legacy systems that many telcos still have hanging around. An ESB can work well in a MicroServices environment too – so don’t think that just because you have a ESB, you’re fighting against MicroServices – you are not. MicroServices can make use of the ESB for connectivity to conventional Web Services (SOA) as well as legacy systems.
A common Orchestration layer would drive consistency in processes at all layers of a Telco – and there are a number of Business Process Management orchestration engines out there that have the flexibility to work with the Integration layer to orchestrate processes from the lowest level (such as within a Network Function Virtualisation (NFV) environment) all the way up to the highest levels of business process – the orchestrations should be defined in an standard language such as Business Process Execution Language (BPEL) or Business Process Model Notation (BPMN).
To me, it makes no sense to re-invent the wheel and have orchestration engines just for the NFV environment, different orchestration engines for the Service Order Management, the Resource Order Management, the Customer Order Management, the Service Assurance, the Billing, the Partner/Supplier management etc etc – all of these orchestration requirements could be handled by a single orchestration engine. Additionally, this would make disaster recovery simpler and faster and cheaper as well (fewer software components to be restored in a disaster situation).
Originally posted on 31May17 to IBM Developerworks (12,500 Views)
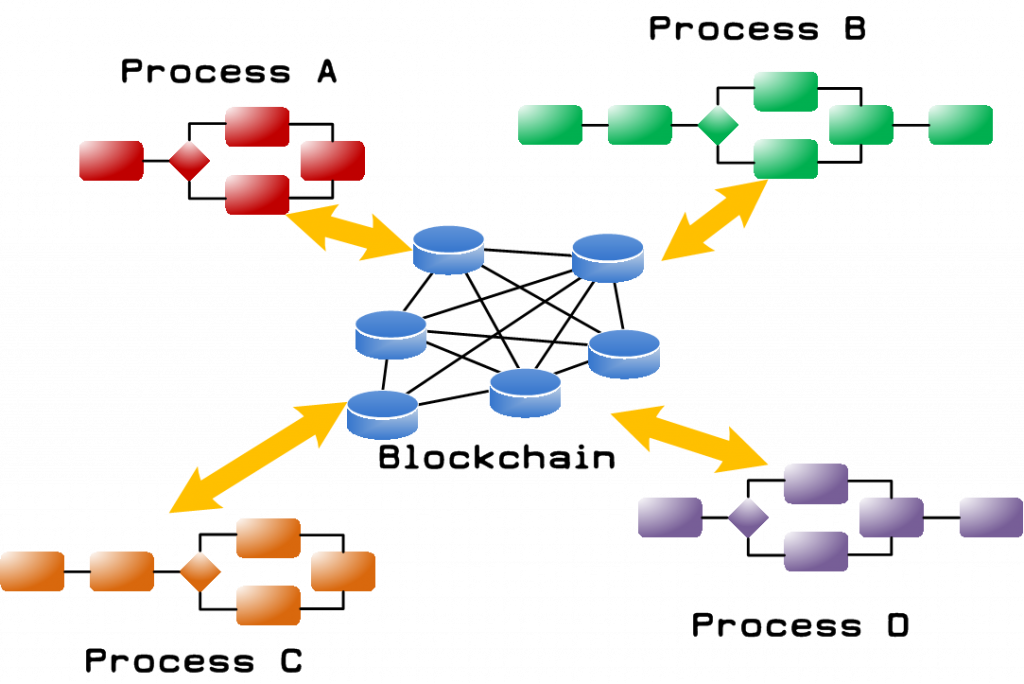
A link to this blog entry (link now broken) popped up in my LinkedIn feed today which in turn linked to a Developerworks article – Combine business process management and blockchain (link now broken) which steps you though a use case and allows you to build your own basic BPM & Blockchain demo. Complex processes could save and get data to/from Blockchain ensuring that every process in any organisation (within the same company and across company boundaries) are using the most up to date data.
I thought it would be appropriate to paste in a link given my previous post on Blockchain in Telcos. As I think about this topic more, I can see a few more use cases in Telecom. I’ll explore them in subsequent posts, but for now, I think it’s important that we be pragmatic about this. Re-engineering processes to make good use of blockchain is non-trivial and therefore will have a cost associated with it. Will the advantages in transparency and resilience be worth the cost of making the changes? Speaking about resilience, don’t forget the damage that a failure can cause. British Airways IT system failure (which I believe is outsourced but I cannot be sure) was down for the better part of three days – failures like that have the potential to bring down a business. We don’t know yet what will happen to BA in the long term, but you certainly don’t want the same sort of failure happening to your business.
Originally posted on 23may17 to IBM Developerworks (16,554 Views)
If you like me are hearing ‘Blockchain this, blockchain that‘, it almost seems like blockchain will solve world peace, global hunger and feed your pets for you! We’re obviously at the ‘peak of inflated expectations’ of the Gartner hype cycle.
I saw a tweet yesterday from an ex-colleague at IBM yesterday that spoke about using blockchain to combat fraud in a Telco. While I can see that as a possible use case, I was thinking about other opportunities for blockchain.
Perhaps I need to explain blockchain briefly so that those that don’t understand it can also understand the Telecom use cases for blockchain. Wikipedia defines it like this:
“A blockchain… is a distributed database that maintains a continuously growing list of records, called blocks, secured from tampering and revision. Each block contains a timestamp and a link to a previous block.By design, blockchains are inherently resistant to modification of the data — once recorded, the data in a block cannot be altered retroactively. Through the use of a peer-to-peer network and a distributed timestamping server, a blockchain database is managed autonomously. Blockchains are “an open, distributed ledger that can record transactions between two parties efficiently and in a verifiable and permanent way. The ledger itself can also be programmed to trigger transactions automatically.”
So, it’s an immutable record of changes to something. I was thinking about that yesterday and there were a number of use cases in Telecom that I could think of that could use blockchain. I’m not suggesting that they should use blockchain or that it’s needed, just that they could. These are the Use cases I came up with:
Fraud prevention : being immutable makes it harder to ‘slip one by’ the normal accounting checks and balances that any large company has. I suppose the real question is ‘exactly which records need to be stored in a blockchain to enable that fraud prevention?’ The obvious one is the billing records.
Billing – maintaining state of post-paid billing accounts, who is making payments, billing amounts and other biulling events (such as rate changes, grace periods etc)
Tracking changes to the network. At the moment, many of the changes being made in a Telco’s network may be made by staff, but increasingly, maintenance and management of the network is being outsourced to external companies and you want to keep en eye on them to ensure they’re doing what they say they’re doing. In the new world of Software Defined Networks (SDN) utilising Network Function Virtualisation (NFV) to build and change the network architecture at a rate that we’ve not seen before, it becomes important for a Telco to be able to track changes to the network to diagnose faults and customer complaints. Over a 24 hour period, a path on a network that supports enterprise customer X may change tens of times – much higher frequency than would be possible if the network elements were physical.
Tracking changes to accounts by customers and telco staff – I could imagine a situation where a customer claims that they didn’t request a configuration change, but a blockchain based record of changes could be used to track beck through all the changes in a customer’s account to determine what happened and when – potentially enabling a Telco to limit the liability to the customer… or vice versa…
Tracking purchases – A blockchain record of purchases would allow a CSP to rebuild a customer’s liability from base information; provided there was an immutable record of the data records as well…
xDRs – any type of Data Record (CDRs, EDRs…) could be stored in a blockchain to facilittate rebuilding of a client’s history and billing records from base data. The problem with using a blockchain to store xDRs is the size requirements. I know that large CSPs in India for example produce between five and ten BILLION records per day. It wouldn’t take long for that to build up to a very large storage requirement – even if you store the mediated data records, it’s going to be very large. I guess the question is : ‘what is the return on investment?’ – it is worth while doing. I can’t think of a business case to justify such an investment, but there may be one out there.
Assurance events – Recording records associated with trouble tickets and problem resolution.
I don’t for a second think that all of these can be justified in terms of cost/benefit analysis, but I could see blockchain being used in these scenarios.
Do you have any ideas? Please leave a comment below.
<edit>
I realise I missed the usual business case that blockchain is used for – a financial ledger. Obviously storing a CSP’s financial data in a blockchain would work (and make sense) as it would in ANY other enterprise. I really wanted to illustrate the CSP specific use cases for blockchain.
Originally posted on 21Mar14 to IBM Developerworks (14,349 Views)
Why TMF Frameworx?
The TeleManagement Forum (TMF) have defined a set of four frameworks collectively known as Frameworx. The key frameworks that will deliver business value to the CSP are the Information Framework(SID) and the Process Framework (eTOM). Both of these can deliver increased business agility – which will reduce time to market and lower IT costs. In particular if a CSP is undertaking with the multiple major IT projects in the near term, TMF Frameworx alignment will ease the pain associated with those major projects.
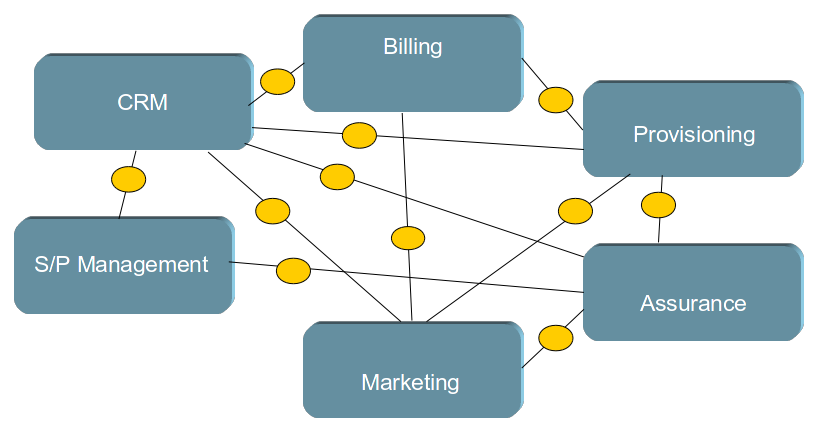
Without a Services Oriented Architecture (SOA), such as many CSP’s have currently, there is no common integration layer, no common way to perform format transformations with that multiple systems can communicate correctly. A typical illustration of this point to point integration might look like the Illustration to the right:
Each of the orange ovals represents a transformation of information so that the two systems can understand each other – each of which must be developed and maintained independently. These transformations will typically be built with a range of different technologies and method, thus increasing the IT costs of integrating, maintaining such transformations, not to mention maintaining competency within the IT organisation.
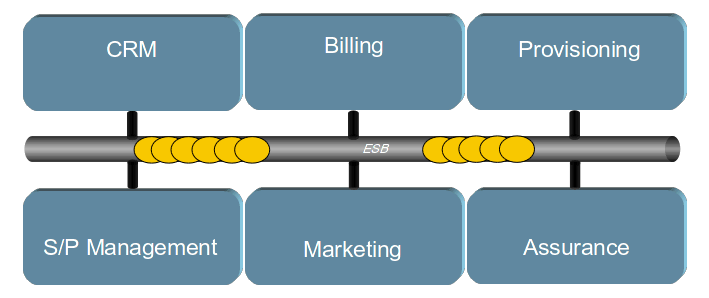
A basic SOA environment introduces the concept of an Enterprise Service Bus which provides a common way to integrate systems together and a common way of building transformation of information model used by multiple systems. The Illustration below shows this basic Services Oriented Architecture – note that we still have the same number of transformations to build and maintain, but now they can be built using a common method, tools and skills.
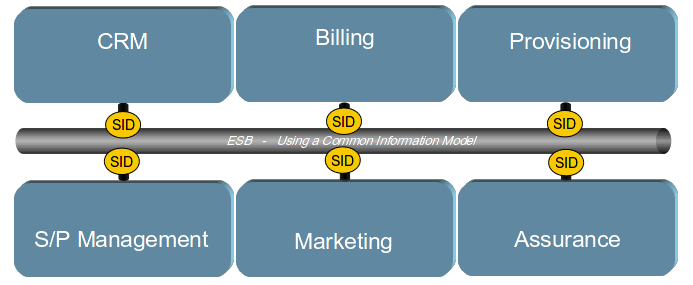
If we now introduce a standard information model such as the SID from the TeleManagement Forum, we can reduce the number of transformation that need to be built and maintained to one per system as shown in the Illustration below. Ensuring that all the traffic across the ESB is SID aligned means that as the CSP changes systems (such as CRM or Billing) the effort required to integrate the new system into the environment is dramatically reduced. That will enable the introduction of new systems faster than could otherwise been achieved. It will also reduce the ongoing IT maintenance costs.
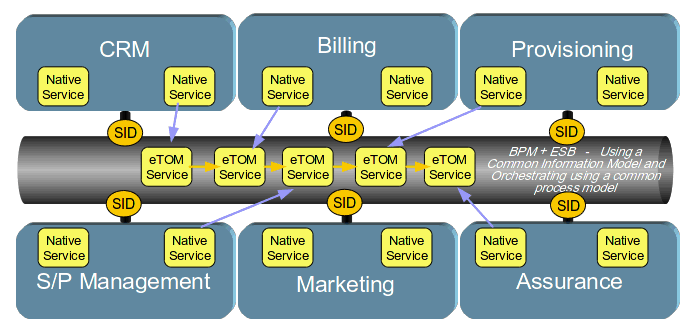
As I’m sure you’re aware, most end to end business processes need to orchestrate multiple systems. If we take the next step and insulate those end to end business processes from the functions that are specific to the various end point systems using a standard Process Framework such as eTOM, then business process can be independent of systems such as CRM, Billing, Provisioning etc. That means that if those systems change in the future (as many CSPs are looking to do) the end to end business processes will not need to change – in fact the process will not even be aware that the end system has changed.
When changing (say) the CRM system, you will need to remap the eTOM business services to the specific native services and rebuild a single integration and a single transformation to/from the standard data model (SID). This is a significant reduction in effort required to introduce new systems into the CSP’s environment. Additionally, if the CSP decide to take a phased approach to the migration of the CRM systems (as opposed to a big bang) the eTOM aligned business processes can dynamically select which of the two CRM systems should be used for this particular process instance.
What that means for the CSP.
Putting in place a robust integration and process orchestration environment that is aligned to TMF Frameworx should be the CSP’s first priority; this will not only allow the subsequent major projects integration and migration efforts to be minimised, it will also reduce the time to market for new processes and product that the CSP might offer into the market.
Telekom Slovenia is a perfect example of this. When the Slovenian government forced Mobitel (Slovenia) and Telekom Slovenia to merge, having the alignment with the SID and eTOM within Mobitel allowed the merged organisation to meet the governments deadlines for the specific target KPIs:
Be able to provide subscribers with a joint bill
Enable CSR from both organisations to sell/service products from both organisations
Offer a quad-play product that combined offerings from both Telekom Slovenia and Mobitel
All within six months.
Recommended Approach
When a CSP is undertaking multiple concurrent major IT replacement projects, there are a number of recommendations that IBM would make based on past observations with other CSPs that have also undertaken significant and multiple system replacement projects:
Use TMF Frameworx to minimise integration work (requires integration and process orchestration environment such as the ESB/SOA project is building) to be in place
Use TMF eTOM to build system independent business processes so that as those major systems change, end to end business processes do not need to change and can dynamically select the legacy or new system during the migration phases of the system replacement projects.
To achieve, 1 and 2, the CSP will need to have the SOA and BPM infrastructure that is capable of integration with ALL of the systems (not just limited to (say) CRM or ERP) within the CSP in place first
If you have the luxury of time, don’t try to run the projects simultaneously, rather run them linearly. If this cannot be achieved due to business constraints, limit the concurrent projects to as few systems as possible, and preferably to systems that don’t have a lot of interaction with each other.
Originally posted on 30Nov12 to IBM Developerworks ( 11,011 Views)
Operators hoping to engage in widespread deployment of voice over LTE in order to gain spectral efficiencies in their network may face some unhappy customers because one vendor’s recent tests showed that VoLTE calls can slash a device’s talk-time battery life by half. Here is the URL for this bookmark: http://www.fiercebroadbandwireless.com/story/study-volte-slashes-smartphone-battery-life-50/2012-11-27 For years now, we’ve known that higher speed mobile networks would mean more power required in handsets to maintain the higher bandwidth connections. I recall it being raised as a concern when UMTS (3G) was being rolled out while GPRS or EDGE were the dominant technology in the mobile data networks. In fact, while I am travelling, I often switch off my 3G/3.5G network capability and trop back to GPRS and EDGE just to make my better last through the day. It’s interesting that it has been quantified like this.
When you think about it though, it makes sense. VoLTE (Voice over LTE) is not using a traditional GSM or CDMA circuit, rather it is using a packet data network to encapsulate the voice traffic – so it is voice over a data network. We’ve known for a long time that data traffic (particularly higher speed data traffic) uses a lot more power than voice traffic. More power equals less talk time from the same charge.
This study is a US based one, so it brings the luggage of CDMA rather than GSM like the rest of the world uses, but I think there are lessons here for the GSM carriers around the world too. CDMA battery life (from my experience) has been on a par with GSM battery life. I think it would be reasonable to equate the CDMA battery life in this study with GSM battery life.
Unfortunately, FireceWireless no longer appears to exist, thus the diagram and the article have disappeared… 🙁
I am seeing more and more countries around the world clawing back the 2G spectrum for use with Digital TV, LTE or other local requirements. At some point in the future (at least for some markets) the only Voice traffic will be using VoLTE and those subscribers will have severely reduced standby and talk time compared to mobile phones of a few years back. Will that lead to a backlash in the community? By that point it may be too late with the spectrum re-deployed for other uses. Will we end up with VoLTE being the only voice option in some countries and others still having CDMA or GSM voice networks – and will that complicate things for phone manufacturers? (remember the days of so called ‘Global phones’ that had to be made to cater to all the different spectrums used around the world – yes multi band phones became pervasive, but will so called Global Phones that retain backward compatibility with GSM networks be so popular when the primary channel for mobile phone distribution is still the telephone carriers themselves (and they have committed to VoLTE in their own country)?
Who knows. I do think that we’ll end up with a big group of primarily voice subscribers who aren’t going to be happy campers!
Originally posted on 29Sep12 to IBM Developerworks (13,053 Views)
Last week, I was at the TeleManagement Forum’s (TMF) Africa Summit event in Johannesburg, South Africa. The main reason for me attending was to finish of my TMF certifications (I am level 3 currently) in the process framework (eTOM) – if I have passed the exam, I will be Level 4 certified. It was a really tough exam (75% pass mark) so I don’t know if I did enough to get over the line’. Regardless, the event was well attended with 200-230 attendees for the two days of the conference. It was interesting to hear the presenter’s thoughts on telco usage within Africa into the future. Many seemed to think that video would drive future traffic for telcos. I am not so sure. I n other markets around the world, video was also projected to drive 3G network adoption, yet this has not happened anywhere. Why do all these people think that Africa will be different? I see similar usage patterns in parts of Asia, yet Video has not take off there. Skype carries many more voice only calls than video calls. Apple’s Facetime video chat hasn’t taken off like Apple predicted. 3G video calls makes a tiny proportion of all calls made. Personally, I think that voice (despite it’s declining popularity relatively speaking in the developed world) will remain the key application, especially voice over LTE for the foreseeable future in Africa. I also think that social networking (be it Facebook, freindster, MySpace or some other African specific tool) will drive consumer data (LTE) traffic. Humans are social animals, and I think these sorts of social interactions will apply just as much in the African scenario as it has in others.
Originally posted on 06Sep12 to IBM Developerworks (15,303 Views)
The other day, I was at a customer proof of concept, where the customer asked for 99.9999% availability within the Proof of Concept environment. Let me explain briefly the environment for the Proof of Concept – we were allocated ONE HP Proliant server, with twelve cores and needed to run the following:
IBM BPM Advanced (BPM Adv)
WebSphere Operational Decision Management (WODM)
WebSphere Services Registry & Repository(WSRR)
Oracle DB (not sure what version the customer installed).
Obviously we needed to use VMWare to deploy the software since installing all of the software on the server (and being able to demonstrate any level of redundancy) would be impossible. Any of you that understand High Availability as I do would say it can’t be done in a Proof of Concept – and I agree, yet our competitor claims they have demonstrated six nines (99.9999% availability) in this Proof of Concept environment – it was deployed on the customer’s hardware; hardware that did not have any redundancy at all. I call shenanigans on the competitor claims. Unfortunately for us, the customer swallowed the claim hook line and sinker. I want to explain why their claim of six nines cannot be substantiated and why the customer should be sceptical as soon as a vendor – any vendor makes such claims. First, lets think about what 99.9999% availability really means. To quantify that figure, that means 31.5 seconds of unplanned downtime per year! For a start, how could you possibly measure availability for a year over a two week period. Our POC server VMs didn’t crash for the entire time we had them running – does that entitle us to claim 100% availability? No way. The simple fact is that the Proof of Concept was deployed in a virtualised environment on a single physical machine – without redundant Hard Drives or power supplies – there is no way we or our competition could possibly claim any level of availability given the unknowns of the environment. In order to achieve high levels of availability, there can be no single point of failure. That means no failure points in the Network, the Hardware or the Software. For example, that means:
Hardware
Multiple redundant Network Interface Connectors
RAID 1+0 drive array,
Multiple redundant power supplies,
Multiple redundant network switches,
Multiple redundant network backbones
Software
Hardened OS
Minimise unused OS services
Use Software clustering capabilities (WebSphere n+x clustering *)
Active automated management of the software and OS
Database replication / clustering (eg Oracle RAC or DB2 HADP)
HA on network software elements (eg DNS servers etc)
We need to go back to the Telco and impress upon them that six nines availability depends on all of the above factors (and probably some others!) and not just about measuring the availability of the software over a short (and non-representative) sample period.
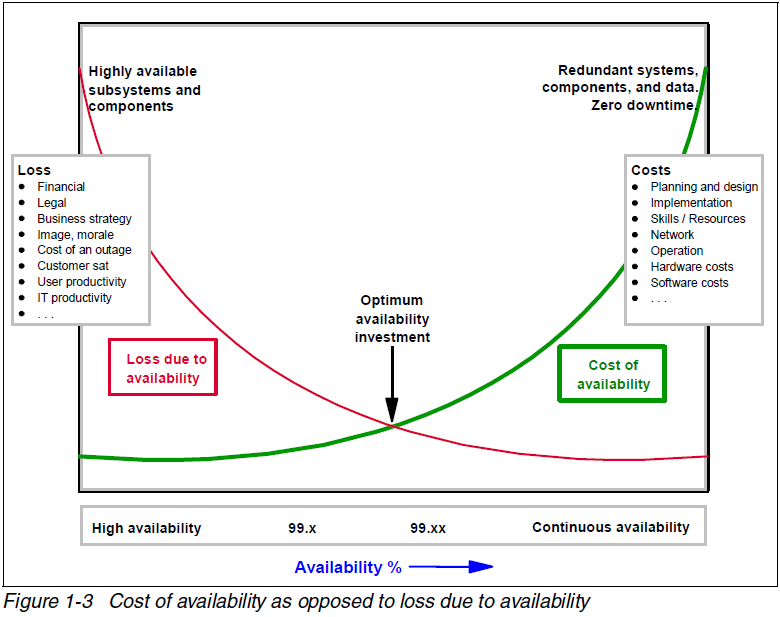
Typically this level of HA is very expensive, indeed every additional ‘9’ increases the cost exponentially – that is: six nines (99.9999% availability) is exponentially more expensive than five nines(99.999% availability). I found this great diagram that illustrates the cost versus HA level.
This diagram is actually from a IBM Redbook (See http://www.redbooks.ibm.com/redbooks/pdfs/sg247700.pdf ) which has a terrific section on high Availability – it illustrates how there is a compromise point between the level of high availability (aiming for continuous availability) and the cost of the infrastructure to provide that level of availability.
* Note:
n is number of servers needed to handle load requirements
x is the number of redundant nodes in the cluster – to achieve six 9’s, this should be in excess of 2)
Originally posted on 22Auc12 to IBM Developerworks (13,006 Views)
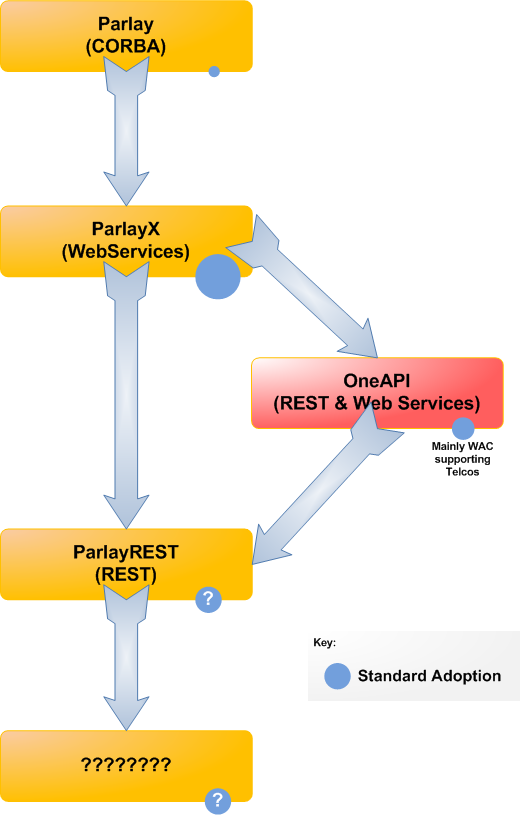
Further to my last post, it now looks like the WAC is completely dead and buried. One thing that is creating a lot of chatter at the moment though is TelcoML (Telco Markup Language) – there it a lot of discussions about it on the TeleManagement Forum (TMF) community site and while I don’t intend to get in a big discussion about TelcoML, I do want to talk about Telco standards in general. The Telco standards that seem to take hold are the ones with strong engineering background – I am thinking of networking standards like SS7, INAP, CAMEL, SigTRAN etc, but the Telco standards focussed on the IT domain (like Parlay, ParlayX, OneAPI, ParlayREST and perhaps TelcoML) seem to struggle to get real penetration – sure standards are good – they make it easier and cheaper for Telcos to integrate and introduce new software; they make it easier for ISVs to build software that can be deployed at any telco. So, why don’t they stick? Why do we see a progression of standards that are well designed, have collaboration of a core set of telcos around the world (I’m thinking the WAC here) yet nothing comes of it. It we look at Parlay for example, sure CORBA is hard, so I get why it didn’t take off, but ParlayX with web services is easy – pretty much every IDE in the world can build a SOAP request from the WSDL for that web Service – why didn’t it take off? I’ve spoken to telcos all around the world about ParlayX, but it’s rare to find one that is truly committed to the standard – sure the RFP’s say must have ParlayX, but then after they implement the software (Telecom Web Services Server in IBM’s case) they either continue to offer their previous in house developed interfaces for those network services and don’t use ParlayX or they just don’t follow through with their plans to expose the services externally: why did we bother? ParlayX stagnated for many years with little real adoption from Telcos. Along comes GSMA with OneAPI with the mantra ‘ParlayX web services are too complicated still, lets simplify them and also provide a REST based interface’. No new services, just the same ones as ParlayX, but simplified. Yes, I responded to a lot of Requests For Proposal (RFP) asking for OneAPI support, but I have not seen one telco that has actually exposed those OneAPI interfaces to 3rd party developers as they originally intended. So, now, OneAPI doesn;t really exist any more and we have ParlayREST as a replacement. Will that get any more take up? I don’t think so. The TMF Frameworx seem to have more adoption, but they are the exception to the rule. I am not really sure why Telco standards efforts have such a tough time of it, but I suspect that it comes down to:
Lack of long term thinking within telcos – there are often too many tactical requirements to be fulfilled and the long term strategy never gets going (this is like Governments who have a four year terms not being able to get 20 year projects over the line – they’re too worried about getting the day to day things patched up and then getting re-elected)
Senior executives in Telcos that truly don’t appreciate the benefits of standardisation – I am not sure if this is because executives come from a non-technical background or some other reason.
What to do? I guess I will keep preaching about standards – it is fundamental to IBM’s strategy and operations after all – and keep up with the new ones as they come along. Lets hope that Telcos start to understand why they should be using standards as much as possible, after all they will make their life easier and their operations cheaper.